MetalLB on Kubernetes, via Helm
MetalLB offers a network load balancer implementation which workes on "bare metal" (as opposed to a cloud provider).
MetalLB does two jobs:
- Provides address allocation to services out of a pool of addresses which you define
- Announces these addresses to devices outside the cluster, either using ARP/NDP (L2) or BGP (L3)
Ingredients
- A Kubernetes cluster
- Flux deployment process bootstrapped
- If k3s is used, then it was deployed with
--disable servicelb
Optional:
- Network firewall/router supporting BGP (ideal but not required)
L3 vs L2
MetalLB can be configured to operate in either Layer 2 or Layer 3 mode (below). See my highly accurate and technically appropriate diagrams below to understand the difference:
Layer 3 (recommended)
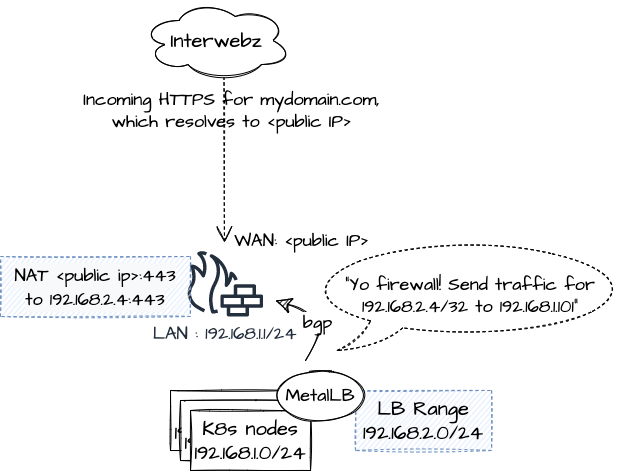
When configuring MetalLB for Layer 3, you define a dedicated subnet to be advertised from your MetalLB pods to your BGP-speaking router/firewall. This subnet shouldn't be configured on any nodes, or any of your network equipment. We are taking advantage of a protocol first designed in 1989 to allow MetalLB to tell your router where to send traffic to this new subnet (it should send it to the Kubernetes nodes, of course, which are on the same network as the router already is).
If you need to access your services externally, then perform NAT on your firewall to the external IP assigned to your LoadBalancerIP Kubernetes service by MetalLB.
Use BGP if possible - it's far easier to debug / monitor than Layer 2 (below)
Layer 2
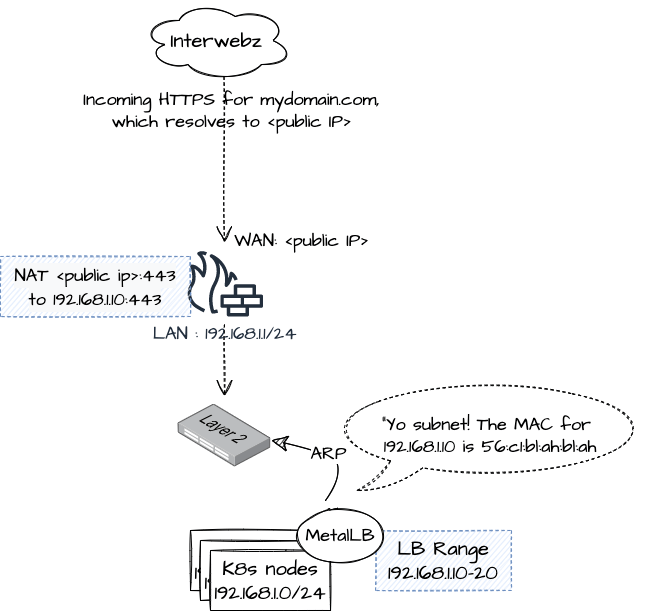
Now we are taking advantage of a protocol first designed in 1982 to "lie to" other devices on your subnet, telling them that the MAC address for a given IP belongs whichever MetalLB pod has the "leader" role for this virtual IP.
As above, if you need to access your services externally, then perform NAT on your firewall to the external IP assigned to your LoadBalancerIP Kubernetes service by MetalLB.
Use Layer 2 if your firewall / router can't support BGP.
MetalLB Requirements
Allocations
You'll need to make some decisions re IP allocations.
- What is the range of addresses you want to use for your LoadBalancer service pool? If you're using BGP, this can be a dedicated subnet (i.e. a /24), and if you're not, this should be a range of IPs in your existing network space for your cluster nodes (i.e., 192.168.1.100-200)
- If you're using BGP, pick two private AS numbers between 64512 and 65534 inclusively.
Namespace
We need a namespace to deploy our HelmRelease and associated ConfigMaps into. Per the flux design, I create this example yaml in my flux repo:
apiVersion: v1
kind: Namespace
metadata:
name: metallb-system
HelmRepository
Next, we need to define a HelmRepository (a repository of helm charts), to which we'll refer when we create the HelmRelease. We only need to do this once per-repository. In this case, we're using the (prolific) metallb chart repository, so per the flux design, I create this example yaml in my flux repo:
apiVersion: source.toolkit.fluxcd.io/v1beta2
kind: HelmRepository
metadata:
name: metallb
namespace: flux-system
spec:
interval: 15m
url: https://metallb.github.io/metallb
Kustomization
Now that the "global" elements of this deployment (Namespace and HelmRepository) have been defined, we do some "flux-ception", and go one layer deeper, adding another Kustomization, telling flux to deploy any YAMLs found in the repo at /metallb-system. I create this example Kustomization in my flux repo:
apiVersion: kustomize.toolkit.fluxcd.io/v1
kind: Kustomization
metadata:
name: metallb--metallb-system
namespace: flux-system
spec:
interval: 15m
path: ./metallb-system
prune: true # remove any elements later removed from the above path
timeout: 2m # if not set, this defaults to interval duration, which is 1h
sourceRef:
kind: GitRepository
name: flux-system
healthChecks:
- apiVersion: apps/v1
kind: Deployment
name: metallb-controller
namespace: metallb-system
What's with that screwy name?
Why'd you call the kustomization
metallb--metallb-system?
I keep my file and object names as consistent as possible. In most cases, the helm chart is named the same as the namespace, but in some cases, by upstream chart or historical convention, the namespace is different to the chart name. MetalLB is one of these - the helmrelease/chart name is metallb, but the typical namespace it's deployed in is metallb-system. (Appending -system seems to be a convention used in some cases for applications which support the entire cluster). To avoid confusion when I list all kustomizations with kubectl get kustomization -A, I give these oddballs a name which identifies both the helmrelease and the namespace.
ConfigMap (for HelmRelease)
Now we're into the metallb-specific YAMLs. First, we create a ConfigMap, containing the entire contents of the helm chart's values.yaml. Paste the values into a values.yaml key as illustrated below, indented 4 spaces (since they're "encapsulated" within the ConfigMap YAML). I create this example yaml in my flux repo at ``:
apiVersion: v1
kind: ConfigMap
metadata:
name: metallb-helm-chart-value-overrides
namespace: metallb-system
data:
values.yaml: |-
# <upstream values go here>
That's a lot of unnecessary text!
Why not just paste in the subset of values I want to change?
You know what's harder than working out which values from a 2000-line values.yaml to change?
Answer: Working out what values to change when the upstream helm chart has refactored or added options! By pasting in the entirety of the upstream chart, when it comes time to perform upgrades, you can just duplicate your ConfigMap YAML, paste the new values into one of the copies, and compare them side by side to ensure your original values/decisions persist in the new chart.
Then work your way through the values you pasted, and change any which are specific to your configuration.
Kustomization for CRs (Config)
Older versions of MetalLB were configured by a simple ConfigMap, which could be deployed into Kubernetes alongside the helmrelease, since a ConfigMap is a standard Kubernetes primitive.
Since v0.13 though, MetalLB is configured exclusively using CRDs (this allows for syntax validation, among other advantages). This means that the custom resources (CRs) have to be applied after MetalLB's helm chart has been deployed, since it's the chart which creates the CRD definitions. So we can't deploy the config CRs in the same kustomization as we deploy the helmrelease (because the CRDs won't exist yet!)
The simplest way to solve this chicken-and-egg problem is to create a second Kustomization for the MetalLB CRs, and make it depend on the first Kustomization (MetalLB itself).
I create this example Kustomization in my flux repo:
apiVersion: kustomize.toolkit.fluxcd.io/v1
kind: Kustomization
metadata:
name: config--metallb-system
namespace: flux-system
spec:
interval: 15m
dependsOn:
- name: metallb--metallb-system
path: ./metallb-config
prune: true # remove any elements later removed from the above path
timeout: 2m # if not set, this defaults to interval duration, which is 1h
sourceRef:
kind: GitRepository
name: flux-system
healthChecks:
- apiVersion: apps/v1
kind: Deployment
name: metallb-controller
namespace: metallb-system
Custom Resources
Finally, it's time to actually configure MetalLB! In my setup, I'm using BGP against a pair of pfsense1 firewalls, so per the official docs, I use the following configurations, saved in my flux repo:
Special location for custom resources
Note that the 3 types of custom resources defined below are saved into a new folder, /metallb-config/, which is referenced by the config--metallb-system Kustomization created above.
IPAddressPool
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: metallb-pool
namespace: metallb-system
spec:
addresses:
- 192.168.32.0/24
BGPAdvertisment
apiVersion: metallb.io/v1beta1
kind: BGPAdvertisement
metadata:
name: metallb-advertisment
namespace: metallb-system
spec:
ipAddressPools:
- metallb-pool
aggregationLength: 32
localPref: 100
communities:
- 65535:65282
BGPPeer(s)
You need separate BGPPeer resource for every BGP peer, from MetalLB's perspective. Because I use dual pfsense firewalls, I maintain two files, each identifying its peer in its filename, like this:
apiVersion: metallb.io/v1beta2
kind: BGPPeer
metadata:
name: bgppeer-192.168.33.2
namespace: metallb-system
spec:
myASN: 64500
peerASN: 64501
peerAddress: 192.168.33.2
Summary
In the config referenced above, I define one pool of addresses (192.168.32.0/24) which MetalLB is responsible for allocating to my services. MetalLB will then "advertise" these addresses to my firewalls (192.168.33.2 and 192.168.33.4), in an eBGP relationship where the firewalls' ASN is 64501 and MetalLB's ASN is 64500.
Provided I'm using my firewalls as my default gateway (a VIP), when I try to access one of the 192.168.32.x IPs from any subnet connected to my firewalls, the traffic will be routed from the firewall to one of the cluster nodes running the pods selected by that service.
Dude, BGP is too complicated!
There's an easier way, with some limitations. If you configure MetalLB in L2 mode, all you need to do is to define your IPAddressPool, and then an L2Advertisment, like this:
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: my-l2-advertisment
namespace: metallb-system
spec:
ipAddressPools:
- metallb-pool
HelmRelease
Lastly, having set the scene above, we define the HelmRelease which will actually deploy MetalLB into the cluster, with the config and extra ConfigMap we defined above. I save this in my flux repo:
apiVersion: helm.toolkit.fluxcd.io/v2beta1
kind: HelmRelease
metadata:
name: metallb
namespace: metallb-system
spec:
chart:
spec:
chart: metallb
version: 0.13.7
sourceRef:
kind: HelmRepository
name: metallb
namespace: flux-system
interval: 15m
timeout: 5m
releaseName: metallb
valuesFrom:
- kind: ConfigMap
name: metallb-helm-chart-value-overrides
valuesKey: values.yaml # This is the default, but best to be explicit for clarity
Why not just put config in the HelmRelease?
While it's true that we could embed values directly into the HelmRelease YAML, this becomes unweildy with large helm charts. It's also simpler (less likely to result in error) if changes to HelmReleases, which affect deployment of the chart, are defined in separate files to changes in helm chart values, which affect operation of the chart.
Deploy MetalLB
Having committed the above to your flux repository, you should shortly see a metallb kustomization, and in the metallb-system namespace, a controller and a speaker pod for every node:
root@cn1:~# kubectl get pods -n metallb-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
metallb-controller-779d8686f6-mgb4s 1/1 Running 0 21d 10.0.6.19 wn3 <none> <none>
metallb-speaker-2qh2d 1/1 Running 0 21d 192.168.33.24 wn4 <none> <none>
metallb-speaker-7rz24 1/1 Running 0 21d 192.168.33.22 wn2 <none> <none>
metallb-speaker-gbm5r 1/1 Running 0 21d 192.168.33.23 wn3 <none> <none>
metallb-speaker-gzgd2 1/1 Running 0 21d 192.168.33.21 wn1 <none> <none>
metallb-speaker-nz6kd 1/1 Running 0 21d 192.168.33.25 wn5 <none> <none>
root@cn1:~#
Why are there no speakers on my masters?
In some cluster setups, master nodes are "tainted" to prevent workloads running on them and consuming capacity required for "mastering". If this is the case for you, but you actually do want to run some externally-exposed workloads on your masters, you'll need to update the speaker.tolerations value for the HelmRelease config to include:
- key: "node-role.kubernetes.io/master"
effect: "NoSchedule"
How do I know it's working?
If you used my template repository to start off your flux deployment strategy, then the podinfo helm chart has already been deployed. By default, the podinfo service is in ClusterIP mode, so it's only reachable within the cluster.
Edit your podinfo helmrelease configmap (/podinfo/configmap-podinfo-helm-chart-value-overrides.yaml), and change this:
<snip>
# Kubernetes Service settings
service:
enabled: true
annotations: {}
type: ClusterIP
<snip>
To:
<snip>
# Kubernetes Service settings
service:
enabled: true
annotations: {}
type: LoadBalancer
<snip>
Commit your changes, wait for a reconciliation, and run kubectl get services -n podinfo. All going well, you should see that the service now has an IP assigned from the pool you chose for MetalLB!
Chef's notes 📓
-
I've documented an example re how to configure BGP between MetalLB and pfsense. ↩
Tip your waiter (sponsor) 👏
Did you receive excellent service? Want to compliment the chef? (..and support development of current and future recipes!) Sponsor me on Github / Ko-Fi / Patreon, or see the contribute page for more (free or paid) ways to say thank you! 👏
Employ your chef (engage) 🤝
Is this too much of a geeky PITA? Do you just want results, stat? I do this for a living - I'm a full-time Kubernetes contractor, providing consulting and engineering expertise to businesses needing short-term, short-notice support in the cloud-native space, including AWS/Azure/GKE, Kubernetes, CI/CD and automation.
Learn more about working with me here.
Flirt with waiter (subscribe) 💌
Want to know now when this recipe gets updated, or when future recipes are added? Subscribe to the RSS feed, or leave your email address below, and we'll keep you updated.