Highly Available Docker Swarm Design
In the design described below, our "private cloud" platform is:
- Highly-available (can tolerate the failure of a single component)
- Scalable (can add resource or capacity as required)
- Portable (run it on your garage server today, run it in AWS tomorrow)
- Secure (access protected with LetsEncrypt certificates and optional OIDC with 2FA)
- Automated (requires minimal care and feeding)
Design Decisions
Where possible, services will be highly available.**
This means that:
- At least 3 docker swarm manager nodes are required, to provide fault-tolerance of a single failure.
- Ceph is employed for share storage, because it too can be made tolerant of a single failure.
Note
An exception to the 3-nodes decision is running a single-node configuration. If you only have one node, then obviously your swarm is only as resilient as that node. It's still a perfectly valid swarm configuration, ideal for starting your self-hosting journey. In fact, under the single-node configuration, you don't need ceph either, and you can simply use the local volume on your host for storage. You'll be able to migrate to ceph/more nodes if/when you expand.
Where multiple solutions to a requirement exist, preference will be given to the most portable solution.
This means that:
- Services are defined using docker-compose v3 YAML syntax
- Services are portable, meaning a particular stack could be shut down and moved to a new provider with minimal effort.
Security
Under this design, the only inbound connections we're permitting to our docker swarm in a minimal configuration (you may add custom services later, like UniFi Controller) are:
Network Flows
- HTTP (TCP 80) : Redirects to https
- HTTPS (TCP 443) : Serves individual docker containers via SSL-encrypted reverse proxy
Authentication
- Where the hosted application provides a trusted level of authentication (i.e., NextCloud), or where the application requires public exposure (i.e. Privatebin), no additional layer of authentication will be required.
- Where the hosted application provides inadequate (i.e. NZBGet) or no authentication (i.e. Gollum), a further authentication against an OAuth provider will be required.
High availability
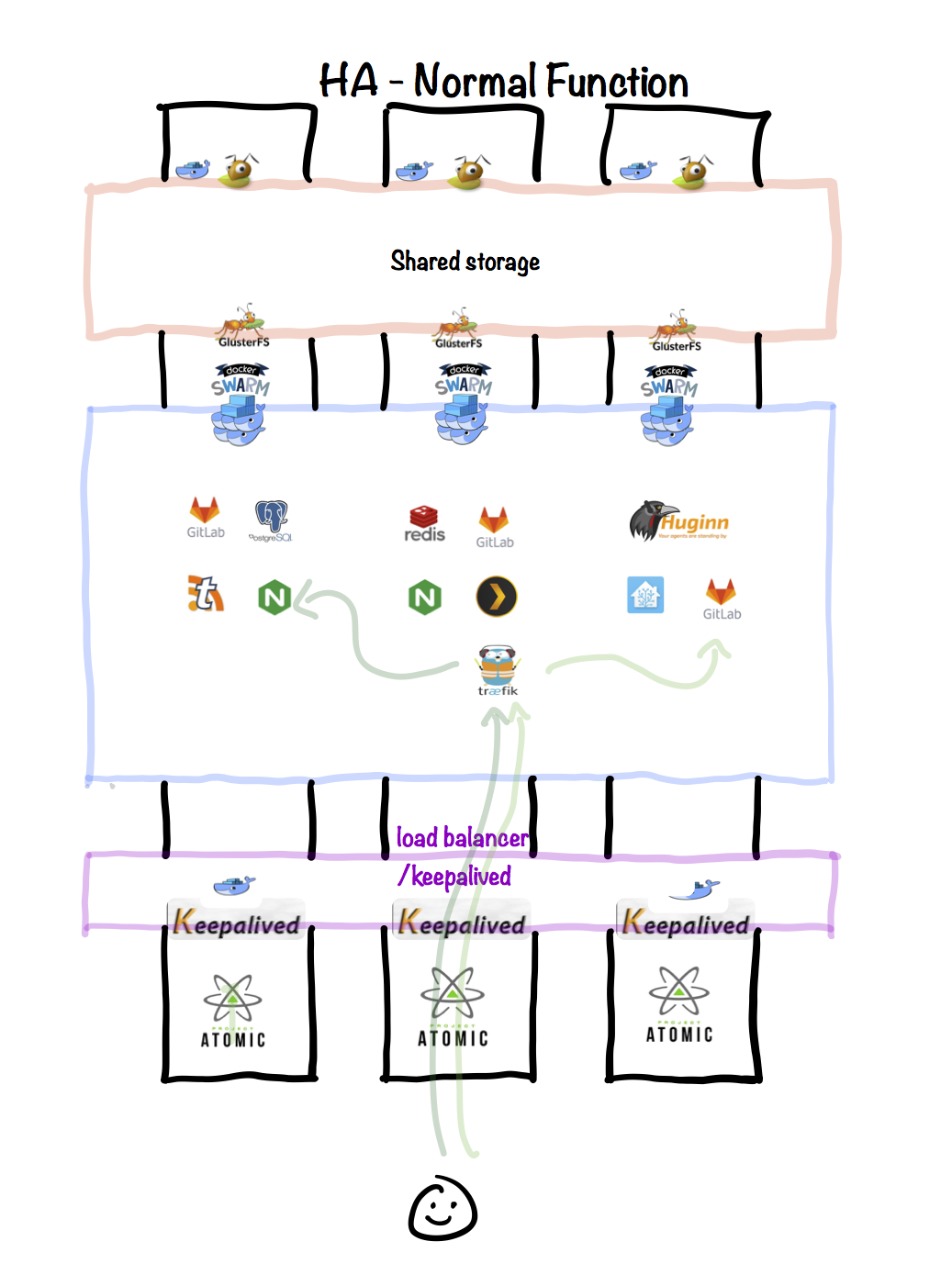
Normal function
Assuming a 3-node configuration, under normal circumstances the following is illustrated:
- All 3 nodes provide shared storage via Ceph, which is provided by a docker container on each node.
- All 3 nodes participate in the Docker Swarm as managers.
- The various containers belonging to the application "stacks" deployed within Docker Swarm are automatically distributed amongst the swarm nodes.
- Persistent storage for the containers is provide via cephfs mount.
- The traefik service (in swarm mode) receives incoming requests (on HTTP and HTTPS), and forwards them to individual containers. Traefik knows the containers names because it's able to read the docker socket.
- All 3 nodes run keepalived, at varying priorities. Since traefik is running as a swarm service and listening on TCP 80/443, requests made to the keepalived VIP and arriving at any of the swarm nodes will be forwarded to the traefik container (no matter which node it's on), and then onto the target backend.
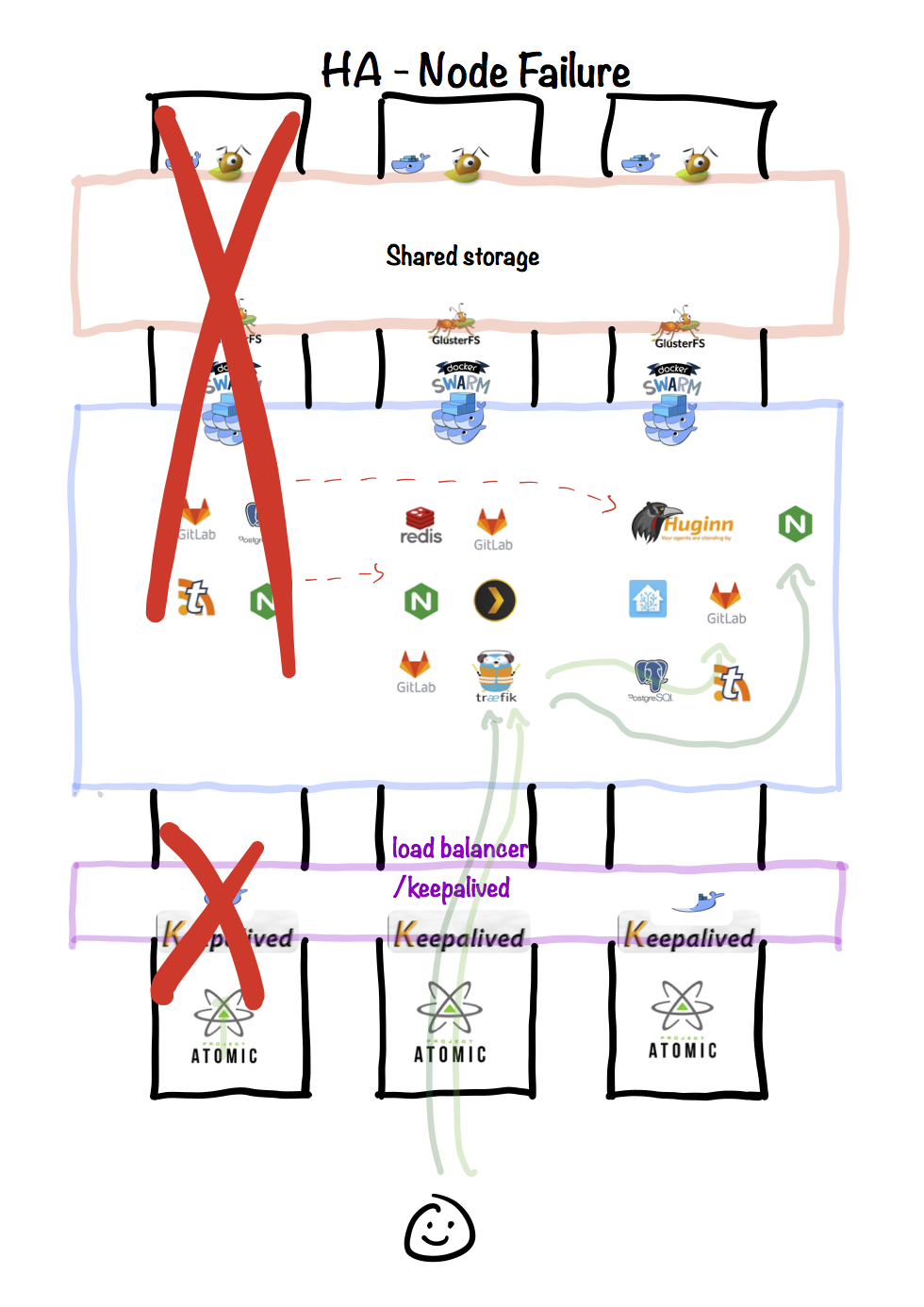
Node failure
In the case of a failure (or scheduled maintenance) of one of the nodes, the following is illustrated:
- The failed node no longer participates in Ceph, but the remaining nodes provide enough fault-tolerance for the cluster to operate.
- The remaining two nodes in Docker Swarm achieve a quorum and agree that the failed node is to be removed.
- The (possibly new) leader manager node reschedules the containers known to be running on the failed node, onto other nodes.
- The traefik service is either restarted or unaffected, and as the backend containers stop/start and change IP, traefik is aware and updates accordingly.
- The keepalived VIP continues to function on the remaining nodes, and docker swarm continues to forward any traffic received on TCP 80/443 to the appropriate node.
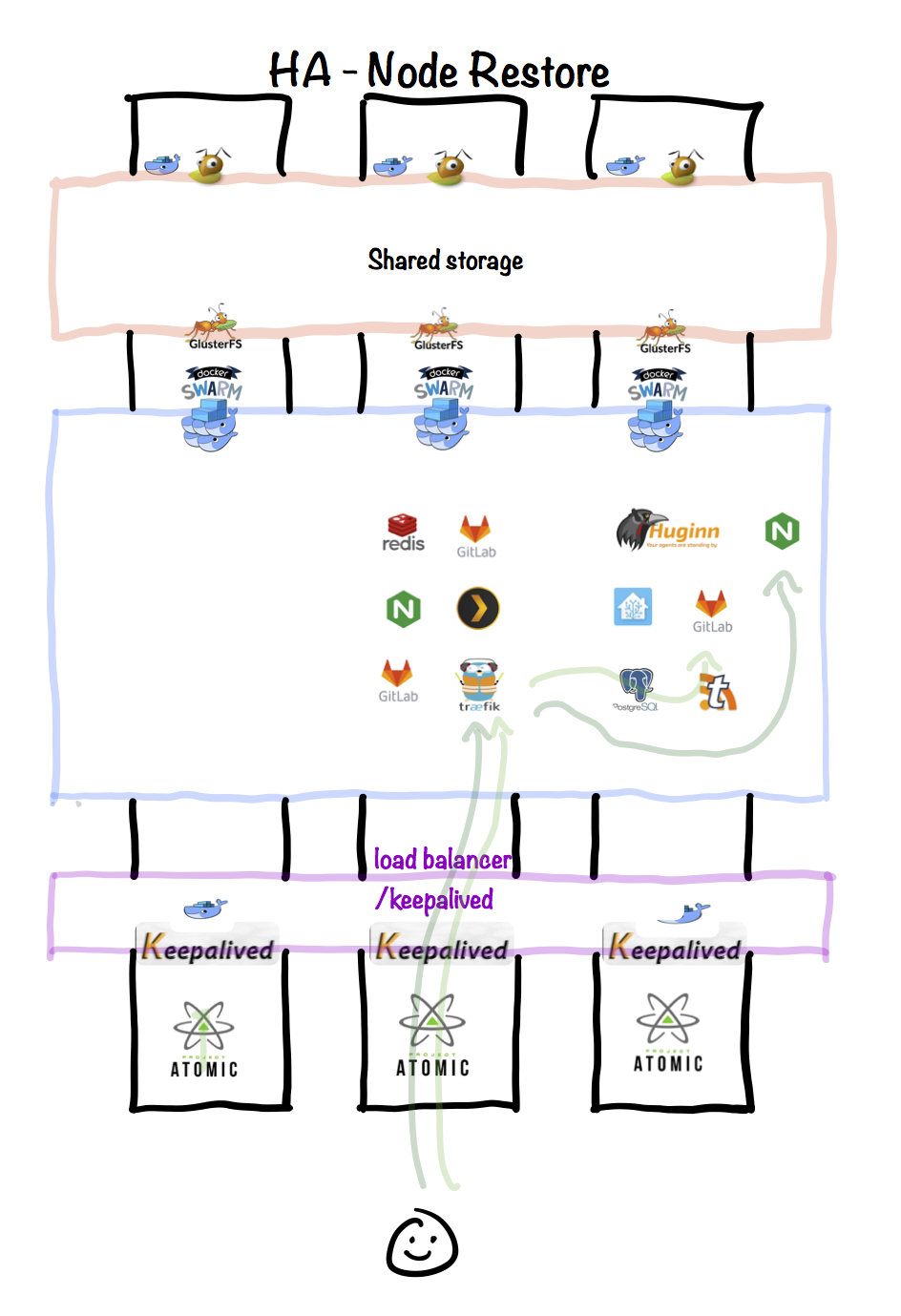
Node restore
When the failed (or upgraded) host is restored to service, the following is illustrated:
- Ceph regains full redundancy
- Docker Swarm managers become aware of the recovered node, and will use it for scheduling new containers
- Existing containers which were migrated off the node are not migrated backend
- Keepalived VIP regains full redundancy
Total cluster failure
A day after writing this, my environment suffered a fault whereby all 3 VMs were unexpectedly and simultaneously powered off.
Upon restore, docker failed to start on one of the VMs due to local disk space issue1. However, the other two VMs started, established the swarm, mounted their shared storage, and started up all the containers (services) which were managed by the swarm.
In summary, although I suffered an unplanned power outage to all of my infrastructure, followed by a failure of a third of my hosts... all my platforms are 100% available1 with absolutely no manual intervention.
Chef's notes 📓
Tip your waiter (sponsor) 👏
Did you receive excellent service? Want to compliment the chef? (..and support development of current and future recipes!) Sponsor me on Github / Ko-Fi / Patreon, or see the contribute page for more (free or paid) ways to say thank you! 👏
Employ your chef (engage) 🤝
Is this too much of a geeky PITA? Do you just want results, stat? I do this for a living - I'm a full-time Kubernetes contractor, providing consulting and engineering expertise to businesses needing short-term, short-notice support in the cloud-native space, including AWS/Azure/GKE, Kubernetes, CI/CD and automation.
Learn more about working with me here.
Flirt with waiter (subscribe) 💌
Want to know now when this recipe gets updated, or when future recipes are added? Subscribe to the RSS feed, or leave your email address below, and we'll keep you updated.