Install Invidious in Kubernetes
YouTube is ubiquitious now. Almost every video I'm sent, takes me to YouTube. Worse, every YouTube video I watch feeds Google's profile about me, so shortly after enjoying the latest Marvel movie trailers, I find myself seeing related adverts on unrelated websites.
Creepy  !
!
As the connection between the videos I watch and the adverts I see has become move obvious, I've become more discerning re which videos I choose to watch, since I don't necessarily want algorithmically-related videos popping up next time I load the YouTube app on my TV, or Marvel merchandise advertised to me on every second news site I visit.
This is a PITA since it means I have to "self-censor" which links I'll even click on, knowing that once I do click the video link, it's forever associated with my Google account 
After playing around with some of the available public instances for a while, today I finally deployed my own instance of Invidious - an open source alternative front-end to YouTube.
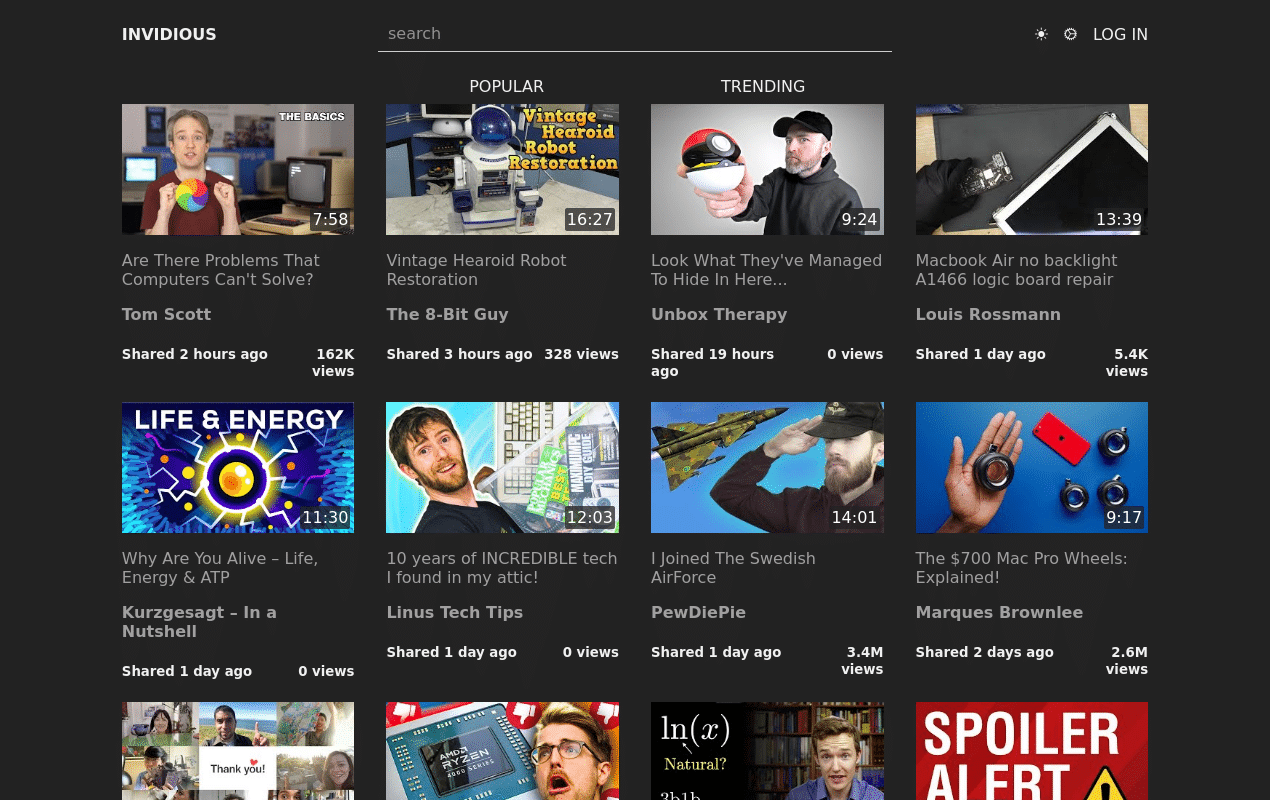
Here's an example from my public instance (yes, running on Kubernetes):
Invidious requirements
Ingredients
Already deployed:
- A Kubernetes cluster (not running Kubernetes? Use the Docker Swarm recipe instead)
- Flux deployment process bootstrapped
- An Ingress controller to route incoming traffic to services
- Persistent storage to store persistent stuff
- External DNS to create an DNS entry
New:
- Chosen DNS FQDN for your instance
Preparation
GitRepository
The Invidious project doesn't currently publish a versioned helm chart - there's just a helm chart stored in the repository (I plan to submit a PR to address this). For now, we use a GitRepository instead of a HelmRepository as the source of a HelmRelease.
apiVersion: source.toolkit.fluxcd.io/v1beta2
kind: GitRepository
metadata:
name: invidious
namespace: flux-system
spec:
interval: 1h0s
ref:
branch: master
url: https://github.com/iv-org/invidious
Namespace
We need a namespace to deploy our HelmRelease and associated ConfigMaps into. Per the flux design, I create this example yaml in my flux repo at /bootstrap/namespaces/namespace-invidious.yaml:
apiVersion: v1
kind: Namespace
metadata:
name: invidious
Kustomization
Now that the "global" elements of this deployment (just the GitRepository in this case) have been defined, we do some "flux-ception", and go one layer deeper, adding another Kustomization, telling flux to deploy any YAMLs found in the repo at /invidious. I create this example Kustomization in my flux repo:
apiVersion: kustomize.toolkit.fluxcd.io/v1
kind: Kustomization
metadata:
name: invidious
namespace: flux-system
spec:
interval: 15m
path: invidious
prune: true # remove any elements later removed from the above path
timeout: 2m # if not set, this defaults to interval duration, which is 1h
sourceRef:
kind: GitRepository
name: flux-system
healthChecks:
- apiVersion: apps/v1
kind: Deployment
name: invidious-invidious # (1)!
namespace: invidious
- apiVersion: apps/v1
kind: StatefulSet
name: invidious-postgresql
namespace: invidious
- No, that's not a typo, just another pecularity of the helm chart!
ConfigMap
Now we're into the invidious-specific YAMLs. First, we create a ConfigMap, containing the entire contents of the helm chart's values.yaml. Paste the values into a values.yaml key as illustrated below, indented 4 spaces (since they're "encapsulated" within the ConfigMap YAML). I create this example yaml in my flux repo:
apiVersion: v1
kind: ConfigMap
metadata:
name: invidious-helm-chart-value-overrides
namespace: invidious
data:
values.yaml: |- # (1)!
# <upstream values go here>
- Paste in the contents of the upstream
values.yamlhere, intended 4 spaces, and then change the values you need as illustrated below.
Values I change from the default are:
postgresql:
image:
tag: 14
auth:
username: invidious
password: <redacted>
database: invidious
primary:
initdb:
username: invidious
password: <redacted>
scriptsConfigMap: invidious-postgresql-init
persistence:
size: 1Gi # (1)!
podAnnotations: # (2)!
backup.velero.io/backup-volumes: backup
pre.hook.backup.velero.io/command: '["/bin/bash", "-c", "PGPASSWORD=$POSTGRES_PASSWORD pg_dump -U postgres -d $POSTGRES_DB -h 127.0.0.1 > /scratch/backup.sql"]'
pre.hook.backup.velero.io/timeout: 3m
post.hook.restore.velero.io/command: '["/bin/bash", "-c", "[ -f \"/scratch/backup.sql\" ] && PGPASSWORD=$POSTGRES_PASSWORD psql -U postgres -h 127.0.0.1 -d $POSTGRES_DB -f /scratch/backup.sql && rm -f /scratch/backup.sql;"]'
extraVolumes:
- name: backup
emptyDir:
sizeLimit: 1Gi
extraVolumeMounts:
- name: backup
mountPath: /scratch
resources:
requests:
cpu: "10m"
memory: 32Mi
# Adapted from ../config/config.yml
config:
channel_threads: 1
feed_threads: 1
db:
user: invidious
password: <redacted>
host: invidious-postgresql
port: 5432
dbname: invidious
full_refresh: false
https_only: true
domain: in.fnky.nz # (3)!
external_port: 443 # (4)!
banner: ⚠️ Note - This public Invidious instance is sponsored ❤️ by <A HREF='https://geek-cookbook.funkypenguin.co.nz'>Funky Penguin's Geek Cookbook</A>. It's intended to support the published <A HREF='https://geek-cookbook.funkypenguin.co.nz/recipes/invidious/'>Docker Swarm recipes</A>, but may be removed at any time without notice. # (5)!
default_user_preferences: # (6)!
quality: dash # (7)! auto-adapts or lets you choose > 720P
- 1Gi is fine for the database for now
- These annotations / extra Volumes / volumeMounts support automated backup using Velero
- Invidious needs this to generate external links for sharing / embedding
- Invidious needs this too, to generate external links for sharing / embedding
- It's handy to tell people what's special about your instance
- Check out the official config docs for comprehensive details on how to configure / tweak your instance!
- Default all users to DASH (adaptive) quality, rather than limiting to 720P (the default)
HelmRelease
Finally, having set the scene above, we define the HelmRelease which will actually deploy the invidious into the cluster. I save this in my flux repo:
apiVersion: helm.toolkit.fluxcd.io/v2beta1
kind: HelmRelease
metadata:
name: invidious
namespace: invidious
spec:
chart:
spec:
chart: ./charts/invidious
sourceRef:
kind: GitRepository
name: invidious
namespace: flux-system
interval: 15m
timeout: 5m
releaseName: invidious
valuesFrom:
- kind: ConfigMap
name: invidious-helm-chart-value-overrides
valuesKey: values.yaml # (1)!
- This is the default, but best to be explicit for clarity
Ingress / IngressRoute
Oddly, the upstream chart doesn't include any Ingress resource. We have to manually create our Ingress as below (note that it's also possible to use a Traefik IngressRoute directly)
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: invidious
namespace: invidious
spec:
ingressClassName: nginx
rules:
- host: in.fnky.nz
http:
paths:
- backend:
service:
name: invidious
port:
number: 3000
path: /
pathType: ImplementationSpecific
An alternative implementation using an IngressRoute could look like this:
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: in.fnky.nz
namespace: invidious
spec:
routes:
- match: Host(`in.fnky.nz`)
kind: Rule
services:
- name: invidious-invidious
kind: Service
port: 3000
Create postgres-init ConfigMap
Another pecularity of the Invidious helm chart is that you have to create your own ConfigMap containing the PostgreSQL data structure. I suspect that the helm chart has received minimal attention in the past 3+ years, and this could probably easily be turned into a job as a pre-install helm hook (perhaps a future PR?).
In the meantime, you'll need to create ConfigMap manually per the repo instructions, or cheat, and copy the one I paste below:
Configmap (click to expand)
apiVersion: v1
kind: ConfigMap
metadata:
name: invidious-postgresql-init
namespace: invidious
data:
annotations.sql: |
-- Table: public.annotations
-- DROP TABLE public.annotations;
CREATE TABLE IF NOT EXISTS public.annotations
(
id text NOT NULL,
annotations xml,
CONSTRAINT annotations_id_key UNIQUE (id)
);
GRANT ALL ON TABLE public.annotations TO current_user;
channel_videos.sql: |+
-- Table: public.channel_videos
-- DROP TABLE public.channel_videos;
CREATE TABLE IF NOT EXISTS public.channel_videos
(
id text NOT NULL,
title text,
published timestamp with time zone,
updated timestamp with time zone,
ucid text,
author text,
length_seconds integer,
live_now boolean,
premiere_timestamp timestamp with time zone,
views bigint,
CONSTRAINT channel_videos_id_key UNIQUE (id)
);
GRANT ALL ON TABLE public.channel_videos TO current_user;
-- Index: public.channel_videos_ucid_idx
-- DROP INDEX public.channel_videos_ucid_idx;
CREATE INDEX IF NOT EXISTS channel_videos_ucid_idx
ON public.channel_videos
USING btree
(ucid COLLATE pg_catalog."default");
channels.sql: |+
-- Table: public.channels
-- DROP TABLE public.channels;
CREATE TABLE IF NOT EXISTS public.channels
(
id text NOT NULL,
author text,
updated timestamp with time zone,
deleted boolean,
subscribed timestamp with time zone,
CONSTRAINT channels_id_key UNIQUE (id)
);
GRANT ALL ON TABLE public.channels TO current_user;
-- Index: public.channels_id_idx
-- DROP INDEX public.channels_id_idx;
CREATE INDEX IF NOT EXISTS channels_id_idx
ON public.channels
USING btree
(id COLLATE pg_catalog."default");
nonces.sql: |+
-- Table: public.nonces
-- DROP TABLE public.nonces;
CREATE TABLE IF NOT EXISTS public.nonces
(
nonce text,
expire timestamp with time zone,
CONSTRAINT nonces_id_key UNIQUE (nonce)
);
GRANT ALL ON TABLE public.nonces TO current_user;
-- Index: public.nonces_nonce_idx
-- DROP INDEX public.nonces_nonce_idx;
CREATE INDEX IF NOT EXISTS nonces_nonce_idx
ON public.nonces
USING btree
(nonce COLLATE pg_catalog."default");
playlist_videos.sql: |
-- Table: public.playlist_videos
-- DROP TABLE public.playlist_videos;
CREATE TABLE IF NOT EXISTS public.playlist_videos
(
title text,
id text,
author text,
ucid text,
length_seconds integer,
published timestamptz,
plid text references playlists(id),
index int8,
live_now boolean,
PRIMARY KEY (index,plid)
);
GRANT ALL ON TABLE public.playlist_videos TO current_user;
playlists.sql: |
-- Type: public.privacy
-- DROP TYPE public.privacy;
CREATE TYPE public.privacy AS ENUM
(
'Public',
'Unlisted',
'Private'
);
-- Table: public.playlists
-- DROP TABLE public.playlists;
CREATE TABLE IF NOT EXISTS public.playlists
(
title text,
id text primary key,
author text,
description text,
video_count integer,
created timestamptz,
updated timestamptz,
privacy privacy,
index int8[]
);
GRANT ALL ON public.playlists TO current_user;
session_ids.sql: |+
-- Table: public.session_ids
-- DROP TABLE public.session_ids;
CREATE TABLE IF NOT EXISTS public.session_ids
(
id text NOT NULL,
email text,
issued timestamp with time zone,
CONSTRAINT session_ids_pkey PRIMARY KEY (id)
);
GRANT ALL ON TABLE public.session_ids TO current_user;
-- Index: public.session_ids_id_idx
-- DROP INDEX public.session_ids_id_idx;
CREATE INDEX IF NOT EXISTS session_ids_id_idx
ON public.session_ids
USING btree
(id COLLATE pg_catalog."default");
users.sql: |+
-- Table: public.users
-- DROP TABLE public.users;
CREATE TABLE IF NOT EXISTS public.users
(
updated timestamp with time zone,
notifications text[],
subscriptions text[],
email text NOT NULL,
preferences text,
password text,
token text,
watched text[],
feed_needs_update boolean,
CONSTRAINT users_email_key UNIQUE (email)
);
GRANT ALL ON TABLE public.users TO current_user;
-- Index: public.email_unique_idx
-- DROP INDEX public.email_unique_idx;
CREATE UNIQUE INDEX IF NOT EXISTS email_unique_idx
ON public.users
USING btree
(lower(email) COLLATE pg_catalog."default");
videos.sql: |+
-- Table: public.videos
-- DROP TABLE public.videos;
CREATE UNLOGGED TABLE IF NOT EXISTS public.videos
(
id text NOT NULL,
info text,
updated timestamp with time zone,
CONSTRAINT videos_pkey PRIMARY KEY (id)
);
GRANT ALL ON TABLE public.videos TO current_user;
-- Index: public.id_idx
-- DROP INDEX public.id_idx;
CREATE UNIQUE INDEX IF NOT EXISTS id_idx
ON public.videos
USING btree
(id COLLATE pg_catalog."default");
Install Invidious!
Commit the changes to your flux repository, and either wait for the reconciliation interval, or force a reconcilliation1 using flux reconcile source git flux-system. You should see the kustomization appear...
~ ❯ flux get kustomizations | grep invidious
invidious main/d34779f False True Applied revision: main/d34779f
~ ❯
The helmrelease should be reconciled...
~ ❯ flux get helmreleases -n invidious
NAME REVISION SUSPENDED READY MESSAGE
invidious 1.1.1 False True Release reconciliation succeeded
~ ❯
And you should have happy Invidious pods:
~ ❯ k get pods -n invidious
NAME READY STATUS RESTARTS AGE
invidious-invidious-64f4fb8d75-kr4tw 1/1 Running 0 77m
invidious-postgresql-0 1/1 Running 0 11h
~ ❯
... and finally check that the ingress was created as desired:
~ ❯ k get ingress -n invidious
NAME CLASS HOSTS ADDRESS PORTS AGE
invidious <none> in.fnky.nz 80, 443 19h
~ ❯
Or in the case of an ingressRoute:
~ ❯ k get ingressroute -n invidious
NAME AGE
in.fnky.nz 19h
Now hit the URL you defined in your config, you'll see the basic search screen. Enter a search phrase ("marvel movie trailer") to see the YouTube video results, or paste in a YouTube URL such as https://www.youtube.com/watch?v=bxqLsrlakK8, change the domain name from www.youtube.com to your instance's FQDN, and watch the fun 2!
You can also install a range of browser add-ons to automatically redirect you from youtube.com to your Invidious instance. I'm testing "libredirect" currently, which seems to work as advertised!
Summary
What have we achieved? We have an HTTPS-protected private YouTube frontend - we can now watch whatever videos we please, without feeding Google's profile on us. We can also subscribe to channels without requiring a Google account, and we can share individual videos directly via our instance (by generating links).
Summary
Created:
- We are free of the creepy tracking attached to YouTube videos!
Chef's notes 📓
Tip your waiter (sponsor) 👏
Did you receive excellent service? Want to compliment the chef? (..and support development of current and future recipes!) Sponsor me on Github / Ko-Fi / Patreon, or see the contribute page for more (free or paid) ways to say thank you! 👏
Employ your chef (engage) 🤝
Is this too much of a geeky PITA? Do you just want results, stat? I do this for a living - I'm a full-time Kubernetes contractor, providing consulting and engineering expertise to businesses needing short-term, short-notice support in the cloud-native space, including AWS/Azure/GKE, Kubernetes, CI/CD and automation.
Learn more about working with me here.
Flirt with waiter (subscribe) 💌
Want to know now when this recipe gets updated, or when future recipes are added? Subscribe to the RSS feed, or leave your email address below, and we'll keep you updated.