Design
Like the Docker Swarm "private cloud" design, the Kubernetes design is:
- Highly-available (can tolerate the failure of a single component)
- Scalable (can add resource or capacity as required)
- Portable (run it in DigitalOcean today, AWS tomorrow and Azure on Thursday)
- Secure (access protected with LetsEncrypt certificates)
- Automated (requires minimal care and feeding)
Unlike the Docker Swarm design, the Kubernetes design is:
- Cloud-Native (While you can run your own Kubernetes cluster, it's far simpler to let someone else manage the infrastructure, freeing you to play with the fun stuff)
- Complex (Requires more basic elements, more verbose configuration, and provides more flexibility and customisability)
Design Decisions
The design and recipes are provider-agnostic**
This means that:
- The design should work on GKE, AWS, DigitalOcean, Azure, or even MicroK8s
- Custom service elements specific to individual providers are avoided
The simplest solution to achieve the desired result will be preferred**
This means that:
- Persistent volumes from the cloud provider are used for all persistent storage
- We'll do things the "Kubernetes way", i.e., using secrets and configmaps, rather than trying to engineer around the Kubernetes basic building blocks.
Insofar as possible, the format of recipes will align with Docker Swarm**
This means that:
- We use Kubernetes namespaces to replicate Docker Swarm's "per-stack" networking and service discovery
Security
Under this design, the only inbound connections we're permitting to our Kubernetes swarm are:
Network Flows
- HTTPS (TCP 443) : Serves individual docker containers via SSL-encrypted reverse proxy (Traefik)
- Individual additional ports we choose to expose for specific recipes (i.e., port 8443 for MQTT)
Authentication
- Other than when an SSL-served application provides a trusted level of authentication, or where the application requires public exposure, applications served via Traefik will be protected with an OAuth proxy.
The challenges of external access
Because we're Cloude-Native now, it's complex to get traffic into our cluster from outside. We basically have 3 options:
-
HostIP: Map a port on the host to a service. This is analogous to Docker's port exposure, but lacking in that it restricts us to one host port per-container, and it's not possible to anticipate which of your Kubernetes hosts is running a given container. Kubernetes does not have Docker Swarm's "routing mesh", allowing for simple load-balancing of incoming connections.
-
LoadBalancer: Purchase a "loadbalancer" per-service from your cloud provider. While this is the simplest way to assure a fixed IP and port combination will always exist for your service, it has 2 significant limitations:
-
Cost is prohibitive, at roughly $US10/month per port
-
You won't get the same fixed IP for multiple ports. So if you wanted to expose 443 and 25 (webmail and smtp server, for example), you'd find yourself assigned a port each on two unique IPs, a challenge for a single DNS-based service, like "mail.batman.com"
-
NodePort: Expose our service as a port (between 30000-32767) on the host which happens to be running the service. This is challenging because you might want to expose port 443, but that's not possible with NodePort.
To further complicate options #1 and #3 above, our cloud provider may, without notice, change the IP of the host running your containers (O hai, Google!).
Our solution to these challenges is to employ a simple-but-effective solution which places an HAProxy instance in front of the services exposed by NodePort. For example, this allows us to expose a container on 443 as NodePort 30443, and to cause HAProxy to listen on port 443, and forward all requests to our Node's IP on port 30443, after which it'll be forwarded onto our container on the original port 443.
We use a phone-home container, which calls a simple webhook on our haproxy VM, advising HAProxy to update its backend for the calling IP. This means that when our provider changes the host's IP, we automatically update HAProxy and keep-on-truckin'!
Here's a high-level diagram:
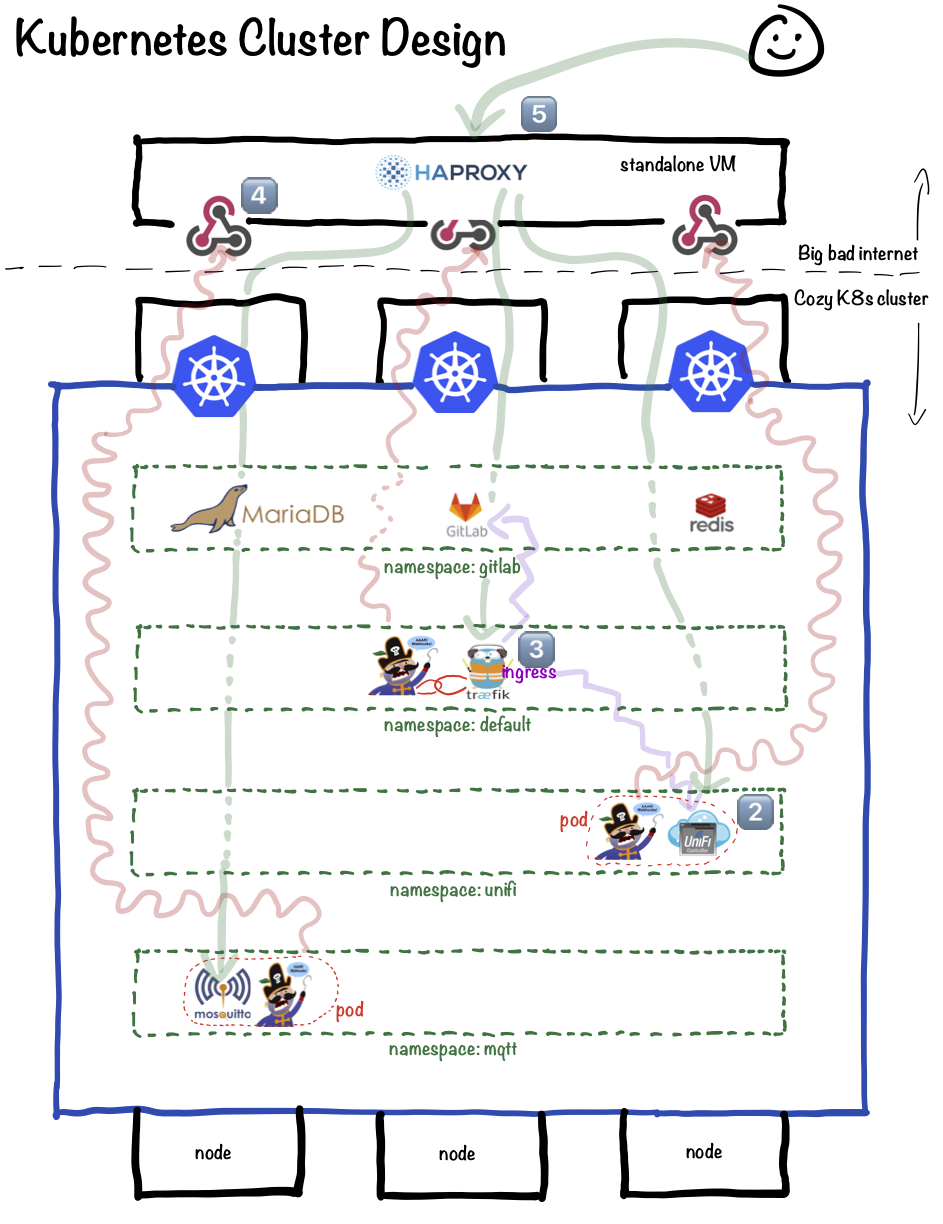
Overview
So what's happening in the diagram above? I'm glad you asked - let's go through it!
Setting the scene
In the diagram, we have a Kubernetes cluster comprised of 3 nodes. You'll notice that there's no visible master node. This is because most cloud providers will give you "free" master node, but you don't get to access it. The master node is just a part of the Kubernetes "as-a-service" which you're purchasing.
Our nodes are partitioned into several namespaces, which logically separate our individual recipes. (I.e., allowing both a "gitlab" and a "nextcloud" namespace to include a service named "db", which would be challenging without namespaces)
Outside of our cluster (could be anywhere on the internet) is a single VM servicing as a load-balancer, running HAProxy and a webhook service. This load-balancer is described in detail, in its own section, but what's important up-front is that this VM is the only element of the design for which we need to provide a fixed IP address.
1 : The mosquitto pod
In the "mqtt" namespace, we have a single pod, running 2 containers - the mqtt broker, and a "phone-home" container.
Why 2 containers in one pod, instead of 2 independent pods? Because all the containers in a pod are always run on the same physical host. We're using the phone-home container as a simple way to call a webhook on the not-in-the-cluster VM.
The phone-home container calls the webhook, and tells HAProxy to listen on port 8443, and to forward any incoming requests to port 30843 (within the NodePort range) on the IP of the host running the container (and because of the pod, tho phone-home container is guaranteed to be on the same host as the MQTT container).
2 : The Traefik Ingress
In the "default" namespace, we have a Traefik "Ingress Controller". An Ingress controller is a way to use a single port (say, 443) plus some intelligence (say, a defined mapping of URLs to services) to route incoming requests to the appropriate containers (via services). Basically, the Trafeik ingress does what Traefik does for us under Docker Swarm.
What's happening in the diagram is that a phone-home pod is tied to the traefik pod using affinity, so that both containers will be executed on the same host. Again, the phone-home container calls a webhook on the HAProxy VM, auto-configuring HAproxy to send any HTTPs traffic to its calling address and customer NodePort port number.
When an inbound HTTPS request is received by Traefik, based on some internal Kubernetes elements (ingresses), Traefik provides SSL termination, and routes the request to the appropriate service (In this case, either the GitLab UI or teh UniFi UI)
3 : The UniFi pod
What's happening in the UniFi pod is a combination of #1 and #2 above. UniFi controller provides a webUI (typically 8443, but we serve it via Traefik on 443), plus some extra ports for device adoption, which are using a proprietary protocol, and can't be proxied with Traefik.
To make both the webUI and the adoption ports work, we use a combination of an ingress for the webUI (see #2 above), and a phone-home container to tell HAProxy to forward port 8080 (the adoption port) directly to the host, using a NodePort-exposed service.
This allows us to retain the use of a single IP for all controller functions, as accessed outside of the cluster.
4 : The webhook
Each phone-home container is calling a webhook on the HAProxy VM, secured with a secret shared token. The phone-home container passes the desired frontend port (i.e., 443), the corresponding NodeIP port (i.e., 30443), and the node's current public IP address.
The webhook uses the provided details to update HAProxy for the combination of values, validate the config, and then restart HAProxy.
5 : The user
Finally, the DNS for all externally-accessible services is pointed to the IP of the HAProxy VM. On receiving an inbound request (be it port 443, 8080, or anything else configured), HAProxy will forward the request to the IP and NodePort port learned from the phone-home container.
Move on..
Still with me? Good. Move on to creating your cluster!
- Start - Why Kubernetes?
- Design (this page) - How does it fit together?
- Cluster - Setup a basic cluster
- Load Balancer - Setup inbound access
- Snapshots - Automatically backup your persistent data
- Helm - Uber-recipes from fellow geeks
- Traefik - Traefik Ingress via Helm
Chef's notes 📓
///Footnotes Go Here///
Tip your waiter (sponsor) 👏
Did you receive excellent service? Want to compliment the chef? (..and support development of current and future recipes!) Sponsor me on Github / Ko-Fi / Patreon, or see the contribute page for more (free or paid) ways to say thank you! 👏
Employ your chef (engage) 🤝
Is this too much of a geeky PITA? Do you just want results, stat? I do this for a living - I'm a full-time Kubernetes contractor, providing consulting and engineering expertise to businesses needing short-term, short-notice support in the cloud-native space, including AWS/Azure/GKE, Kubernetes, CI/CD and automation.
Learn more about working with me here.
Flirt with waiter (subscribe) 💌
Want to know now when this recipe gets updated, or when future recipes are added? Subscribe to the RSS feed, or leave your email address below, and we'll keep you updated.